Transformers in Machine Learning
Thanks largely to the arrival of Transformers, the discipline of machine learning has recently seen a spectacular change. The way we tackle diverse challenges in the field of artificial intelligence has changed as a result of these adaptable and potent models. Transformers were initially developed for natural language processing (NLP), but they have since found use in speech recognition, computer vision, recommendation systems, and other fields as well. The interesting world of Transformers, their architecture, and their influence on the machine learning environment will all be covered in this blog.
READ
Category

With the publication of the paper "Attention Is All You Need" by Vaswani et al. in 2017, Transformers made their debut. With the help of a ground-breaking new mechanism known as "self-attention" or "scaled dot-product attention," the model was able to evaluate the relative value of various input sequence components. Transformers soon beat established models like RNNs and LSTMs on a variety of benchmark tasks, ushering in a new age in NLP.
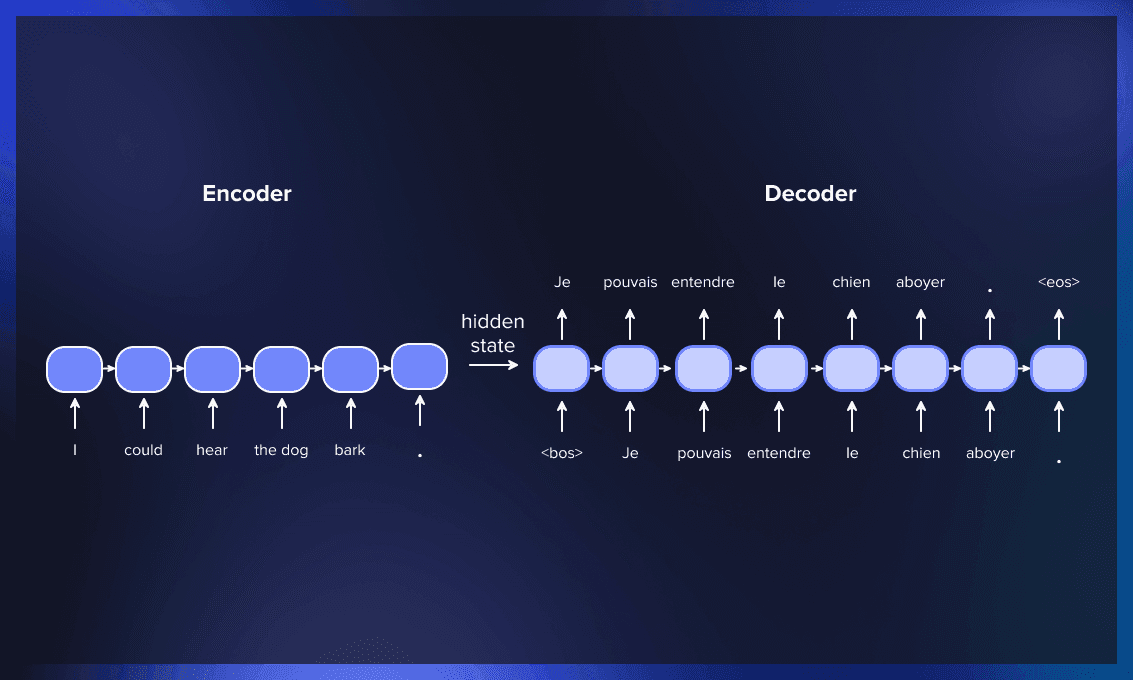

At the heart of a Transformer model lies its unique architecture, which consists of three main components: the encoder, the decoder, and the attention mechanism.
Encoder: The input data must be processed by the encoder. It is made up of several layers, each of which has two sublayers: a feedforward neural network and a multi-head self-attention mechanism. The self-attention mechanism makes the model extremely parallelizable and effective by enabling it to simultaneously record relationships between various words in the input sequence.
Decoder: On the other hand, language production and sequence-to-sequence operations employ the decoder. It also has a number of levels, including sub-layers for self-attention and feedforward. It also has an encoder-decoder attention mechanism that aids in the model's ability to concentrate on crucial input sequence segments while creating an output sequence.
Attention Mechanism: Transformers' primary innovation is its self-attention mechanism. It enables the model to weigh various input sequence components differently depending on how pertinent they are to the word or token currently being analyzed. This approach, which has shown to be useful in NLP applications, captures long-range dependencies.

Transformers have made a significant impact on a wide range of machine learning tasks:
Natural Language Processing (NLP): Transformers have become the go-to architecture for NLP tasks, including sentiment analysis, named entity recognition, machine translation, and text generation. Models like BERT, GPT, and T5 have set state-of-the-art results in these domains.
Computer Vision: Vision Transformers (ViTs) have extended the Transformer architecture to the domain of computer vision. These models have achieved impressive results on image classification, object detection, and image generation tasks.
Speech Recognition: Transformers have also found applications in speech recognition, improving the accuracy and efficiency of automatic speech recognition systems.
Recommendation Systems: Transformers have been employed in recommendation systems, enabling better personalization and understanding of user preferences in platforms like Netflix and Amazon.



